Информативность частотных характеристик N-грамм текстовых фрагментов
Аннотация
Дата поступления статьи: 29.12.2012Рассматривается построение методики информативности частотных характеристик N-грамм текстовых фрагментов интернет-сайтов для формирования дополнительного признака их принадлежности к неявным группам. На основе её применения показано, что частотные характеристики N-грамм обладают достаточной степенью информативности для совершенствования поисковых систем, при этом существует неравномерное распределение зависимости их информативности от выбора неявных групп. Разработанная методика обладает большой общностью в отношении систем письменности, поскольку не опирается только на алфавитные системы.
Ключевые слова: N-грамма, математическая лингвистика, поисковая система, поисковый запрос
05.13.01 - Системный анализ, управление и обработка информации (по отраслям)
Поиск информации в Интернет-среде уже невозможно представить без использования поисковых систем. В настоящее время в них реализуются разнообразные алгоритмы и принципы поиска, при этом процесс совершенствования таких систем реализуется уже с 1994 года (с момента открытия первого проекта каталога сайтов для организации доступа к информационным ресурсам сети – сайт Yahoo.com). Тем не менее, пользователи не всегда удовлетворены результатами обращения к ним. Ряд интересных фактов, связанных с взаимоотношением пользователей и поисковых систем приведены на сайте [1]: пользователи бросают поиски после 12 минут бесплодных попыток; около 75% пользователей разочаровываются при поиске информации в Интернете.
Отметим, что качество предоставляемых пользователю ответов в существенной мере зависит от сформированного запроса. Однако в силу ряда обстоятельств пользователь не всегда в состоянии достаточно точно сформулировать запрос и количество полученных им ответов становится большим. В этих ситуациях дополнительным признаком отбора релевантных ответов может являться принадлежность текстовых документов к той или иной неявной группе. Неявность группы проявляется в том, что принадлежность текста к ней определяется не прямым сравнением с эталонными (ключевыми) словами, а по соответствию смысловым признакам, формулировка которых в искомом тексте отсутствует. Например, пользователь хочет найти описание сказочного персонажа – летающей собаки с именем «Фалькорн». Он точно знает, что это персонаж художественного произведения, автора и название которого он не помнит. По ключевым словам «Фалькорн», «летающая собака» число ссылок очень велико и их просмотр утомителен (возможно займёт более 12 минут, что неминуемо классифицирует эту попытку обращения к поисковой системе как неуспешную). При добавлении ключевых слов «художественное произведение» или «сказка» ситуация существенно не улучшается, поскольку в самом произведении (сайте, содержащем искомую информацию) этих слов может и не быть. Дополнительный отслеживаемый признак позволил бы значительно сократить число сайтов-результатов поиска, отсекая информацию просто о летающих собаках.
Такая оценка принадлежности текстовых фрагментов интернет-сайтов к выбранной неявной группе может быть реализована на основе аппарата теории математической лингвистики [2], которая изучает закономерности лингвистических объектов.
Относительно рассматриваемого направления следует выделить работы, в которых для решения практических задач применяется устойчивость частот отдельных символов и их сочетаний заданной длины N (N-грамм). Так в работе В. Канвара и Дж. Тренкла [3] был предложен метод определения языка документа, основанный на сравнении частот N-грамм текста с их частотами для различных языков. В работе [4] N-граммы уровня символов применены для семантической классификации незнакомых собственных имён, а в статье [5] анализируется содержание и применение N-грамм как средства фиксации языковых реалий и показывается соотношение моделей N-грамм, формальной грамматики и теории случайных марковских процессов. Делается вывод о широких возможностях таких моделей для автоматического анализа печатных текстов. Следует отметить, что в теории поиска как физических, так и информационных объектов также широко применяются марковские модели [6] – [10]. Но до их применения следует сначала оценить информативность соответствующих признаков.
Однако информативность частотных характеристик N-грамм текстовых фрагментов интернет-сайтов для формирования дополнительного признака их принадлежности к неявным группам для совершенствования поисковых систем ещё не рассматривалась.
Целью работы является оценка возможности применения частотных характеристик N-грамм текстовых фрагментов интернет-сайтов для совершенствования поисковых систем на основе исследования их информативности.
Постановка задачи
Пусть определён корпус текстовых документов (фрагментов текстов, являющихся содержанием страниц интернет-сайтов) общим объёмом M знаков, распределённых по V темам (неявным группам). Суммарные объёмы фрагментов, относящихся к каждой n-ой теме (![]() ) известны, и соответственно равны
) известны, и соответственно равны ![]() ,
, ![]() . Значения
. Значения ![]() ,
, ![]() являются значительными для оценки частотных характеристик каждого общего текста темы (неявной группы).
являются значительными для оценки частотных характеристик каждого общего текста темы (неявной группы).
Требуется оценить информативность частотных характеристик текстовых фрагментов интернет-сайтов для формирования дополнительного признака их принадлежности неявным группам для совершенствования поисковых систем.
Разработка методики исследования
На подготовительном этапе для выбранного языка составляются возможные последовательности значащих символов системы письменности длиной не более N: ![]() ,
, ![]() . К незначащим символам можно отнести цифры, знаки пунктуации, пробелы и т.п. Если число значащих символов системы письменности обозначить через
. К незначащим символам можно отнести цифры, знаки пунктуации, пробелы и т.п. Если число значащих символов системы письменности обозначить через ![]() , то число возможных последовательностей значащих символов длиной не более N для этой системы письменности определяется по выражению:
, то число возможных последовательностей значащих символов длиной не более N для этой системы письменности определяется по выражению:
![]() . (1)
. (1)
Функциональная зависимость в выражении (1) представлена только от N, поскольку реального механизма влияния на ![]() не имеется.
не имеется.
Для каждой n-ой неявной группы подсчитывается число использований N-грамм ![]() :
: ![]() .
.
Тогда групповые частоты определяются по выражениям вида:
 ,
, ![]() ,
, ![]() . (2)
. (2)
Применение выражения (2) подразумевает знание (подсчёт) числа использований всех![]() последовательностей. Однако поскольку в приложениях используется ограниченное число наиболее употребительных N-грамм
последовательностей. Однако поскольку в приложениях используется ограниченное число наиболее употребительных N-грамм ![]() (для идентификации языка текста в соответствии с [3] – не более 300), то вычисления по выражению (2) требуют использование неоправданно больших ресурсов (для
(для идентификации языка текста в соответствии с [3] – не более 300), то вычисления по выражению (2) требуют использование неоправданно больших ресурсов (для ![]() величина
величина ![]() для
для ![]() принимает значение
принимает значение ![]() ,
, ![]() ,
, ![]() ).
).
Более «экономным» с вычислительной точки зрения является применение относительных частот вида
![]() ,
, ![]() ,
, ![]() . (3)
. (3)
Проверка гипотезы о возможности такой замены приведена в экспериментальной части статьи.
Более того, поскольку наиболее употребительные N-граммы в каждой неявной группе могут породить различные наборы последовательностей, а для реализации сравнительных процедур, как правило, требуется использование соотносимых наборов, то для определения отсортированного по убыванию набора ![]() N-грамм
N-грамм ![]() ,
, ![]() для заданного корпуса текстовых документов требуется выполнение процедуры следующего вида:
для заданного корпуса текстовых документов требуется выполнение процедуры следующего вида:
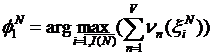 ,
, 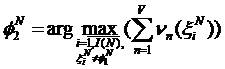 ,
,
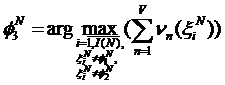 ,… ,
,… ,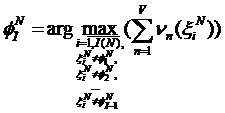 . (4)
. (4)
Тогда с учётом (4) относительные частоты соотносимых наборов N-грамм могут быть получены по выражениям:
![]() ,
, ![]() ,
, ![]() . (5)
. (5)
Пусть некоторый l-ый текстовый фрагмент интернет-сайта требуется отнести к одной из V неявных групп. Объём этого фрагмента составляет ![]() знаков. Тогда относительные частоты соотносимых наборов N-грамм для этого фрагмента вычисляются по выражениям:
знаков. Тогда относительные частоты соотносимых наборов N-грамм для этого фрагмента вычисляются по выражениям:
![]() ,
, ![]() , (6)
, (6)
где ![]() – число использований N-граммы
– число использований N-граммы ![]() в l-ом текстовом фрагменте.
в l-ом текстовом фрагменте.
По полученным значениям относительных частот (5) и (6) можно организовать процедуру сравнения и оценки принадлежности l-го текстового фрагмента интернет-сайта к одной из V неявных групп.
Одним из наиболее простых способов её организации является:
1. Расчёт выборочных коэффициентов корреляции Пирсона [11], c. 128:
 , (7)
, (7)
![]() .
.
2. Принятие решения о принадлежности текстового фрагмента ![]() к одной из неявных групп
к одной из неявных групп ![]() ,
, ![]() в соответствии с правилом:
в соответствии с правилом:
![]() . (8)
. (8)
Естественно, что могут решаться и другие задачи, например, проверка статистической гипотезы о значимости коэффициентов корреляции, равенстве их между собой и т.д.
Результаты исследования
Проведём экспериментальное исследование в соответствии с разработанной методикой. В качестве источника фрагментов текстов, являющихся содержанием страниц интернет-сайтов, выберем англоязычный сайт [12], на котором представлены материалы по различным темам. Выберем четыре темы: «Сomputers & Internet», «Music and Movies», «Pets and Animals» и «Politics and Government» и поставим им в соответствие значение n в порядке перечисления. Примем значение N , равное 3 (в работе [3] N принимает значения от 1 до 5).
Для сформированного корпуса: ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
Для оценки качества последовательностей были рассчитаны выборочные парные коэффициенты корреляции между различными парами множеств ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , представленные в таблице № 1.
, представленные в таблице № 1.
Таблица № 1
Выборочные парные коэффициенты корреляции
|
|
|
|
|
|
|
|
|
18278 |
0,997207 |
0,996013 |
0,996548 |
0,997745 |
0,997745 |
0,995870 |
|
1000 |
0,997075 |
0,996412 |
0,995821 |
0,997653 |
0,997667 |
0,995686 |
|
500 |
0,997169 |
0,995801 |
0,996403 |
0,997733 |
0,997743 |
0,995610 |
|
400 |
0,997216 |
0,995784 |
0,996374 |
0,997793 |
0,997772 |
0,995560 |
|
300 |
0,997221 |
0,995759 |
0,996347 |
0,997802 |
0,997769 |
0,995478 |
|
200 |
0,997191 |
0,995767 |
0,996212 |
0,997962 |
0,997769 |
0,995470 |
|
100 |
0,997039 |
0,995454 |
0,995897 |
0,997966 |
0,997692 |
0,995265 |
Максимальное относительное отклонение
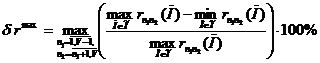 ,
,
![]() , при уменьшении
, при уменьшении ![]() с
с ![]() до
до ![]() составило 0,096%.
составило 0,096%.
Таким образом, косвенно подтверждается гипотеза о возможности существенного ограничения числа рассматриваемых наиболее употребительных N-грамм ![]() при решении прикладных задач.
при решении прикладных задач.
Для оценки принадлежности произвольного l-го текстового фрагмента ![]() на тему «Сomputers & Internet» к одной из неявных групп
на тему «Сomputers & Internet» к одной из неявных групп ![]() ,
, ![]() и исследования информативности частотных характеристик N-грамм положим, что
и исследования информативности частотных характеристик N-грамм положим, что
![]() ,
, ![]() , (9)
, (9)
где ![]() – обозначение j-ой случайной величины, распределённой по нормальному закону с нулевым математическим ожиданием и средним квадратичным отклонением (СКО)
– обозначение j-ой случайной величины, распределённой по нормальному закону с нулевым математическим ожиданием и средним квадратичным отклонением (СКО) ![]() ,
, ![]() – параметр вариации,
– параметр вариации,  .
.
Отметим, что при моделировании частотных характеристик N-грамм текстовых фрагментов относительно выражения (2) в соответствии с подходом, определяемым выражением (9), значения выборочных коэффициентов корреляции, рассчитанные по выражению, соответствующему (7), оказались равны аналогичным выборочным коэффициентам упрощённой модели (выражение (3)).
Результаты оценки вероятности неправильного решения о принадлежности текстовых фрагментов с частотными характеристиками N-грамм, полученных по выражению (9), для различных значений ![]() и
и ![]() при числе реализаций моделирования случайных величин равном 100 (100 различных фрагментов) и процедуре принятия решения (7), (8), представлены в таблице №2.
при числе реализаций моделирования случайных величин равном 100 (100 различных фрагментов) и процедуре принятия решения (7), (8), представлены в таблице №2.
Таблица №2
Оценки вероятностей неправильного решения о принадлежности текстовых фрагментов
|
|
|
|
|
|
18278 |
0,00 |
0,01 |
0,05 |
|
1000 |
0,00 |
0,01 |
0,06 |
|
500 |
0,00 |
0,02 |
0,14 |
|
400 |
0,00 |
0,01 |
0,11 |
|
300 |
0,00 |
0,01 |
0,14 |
|
200 |
0,00 |
0,02 |
0,16 |
|
100 |
0,00 |
0,03 |
0,21 |
Из анализа таблицы видно, что текстовые фрагменты надёжно классифицируются при величинах СКО составляющих практически до 10% от значений относительных частот соответствующих N-грамм. При этом уменьшение числа рассматриваемых отсортированных по убыванию относительной частоты N-грамм существенно сказывается только для величин СКО превышающих 10% от значений относительных частот этих N-грамм.
Заключение
Использована закономерность математической лингвистики: каждый из символов встречается в тексте с определенной частотой и обладает особыми валентностями, т. е. лингвистическими способностями сочетаться с другими символами [2]. Отметим, что рассматриваемая методика обладает большой общностью в отношении систем письменности, поскольку не опирается только на алфавитные системы.
Выводы:
1. Частотные характеристики N-грамм текстовых фрагментов интернет-сайтов обладают достаточной степенью информативности для совершенствования поисковых систем на их основе.
2. Существует неравномерное распределение зависимости информативности частотных характеристик N-грамм текстовых фрагментов интернет-сайтов от неявных групп (в условиях рассмотренного примера более различимыми оказались пары тем «Сomputers & Internet»–«Pets and Animals», «Сomputers & Internet»–«Politics and Government» и «Pets and Animals»–«Politics and Government», т.е. важной задачей является выбор и описание соответствующей неявной группы.
Литература
1. Я мыслю, следовательно, раскручиваю // Исследования и статистика в области интернета, интернет рекламы и продвижения сайта. [Электронный ресурс]: http://digits.ru (дата обращения: 20.12.2012).
2. Пиотровский Р.Г., Бектаев К.Б., Пиотровская А.А. Математическая лингвистика. Учеб. пособ. М.: Высш. шк. 1977. – 383 с.
3. Cavnar W. B., Trenkle J. M. N-Gram-Based Text Categorization // In Proceedings of Third Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, UNLV Publications. 1994.
4. Нехай И.В. Применение N-грамм и других статистик уровня символов и слов для семантической классификации незнакомых собственных имён // Международная конференция по компьютерной лингвистике. [Электронный ресурс]: http://www.dialog-21.ru/digests/dialog2012/materials/pdf/150.pdf (дата обращения: 20.12.2012).
5. Гудков В.Ю., Гудкова Е.Ф. N-граммы в лингвистике // Вестник Челябинского университета. – 2011. – №24 (239). Филология. Искусствоведение. – Вып. 57. – С. 69 – 71.
6. Строцев А.А. Иващенко И.Л. Синтез оптимального управления многопозиционной информационной системой при поиске группы динамических объектов // Известия высших учебных заведений. Радиоэлектроника. – 2005. – Т.48. – №10. – С. 37–45.
7. Строцев А.А. Совместное оптимальное управление поиском и наблюдениями за условно детерминированными динамическими объектами в импульсной многоканальной измерительно-поисковой системе // Известия высших учебных заведений. Радиоэлектроника. – 2004. – Т.47. – №9. – С. 22–29.
8. Строцев А.А. Оптимизация поиска и наблюдений многоканальной импульсной радарной станции в составе многопозиционной комплексной измерительно-поисковой системы // Автоматика и вычислительная техника. – 2004. – №3. – С. 12–21.
9. Развитие PageRank // [Электронный ресурс]: http://ornitos.blogspot.ru (дата обращения: 20.12.2012).
10. Грищук Т.В. Получение характеристической обсервации скрытой марковской модели // Наукові праці ВНТУ. – 2007. – № 1.
11. Третьяк Л.Н. Обработка результатов наблюдений. Оренбург: ГОУ ОГУ, 2004. – 171 с.
12. ArticleCity.com // Free Articles For Reprint. [Электронный ресурс]: http://www.articlecity.com (дата обращения: 20.12.2012).