Модификация модели векторного пространства для ранжирования документов
Аннотация
Рациональная организация информационного поиска является достаточно важной научно-технической и практической задачей, которая неразрывно связана с эффективностью и скоростью принятия решений, как в управлении, так и в других областях человеческой деятельности. Достаточно широкое распространение получила модель векторного пространства рассмотренная в данной статье.
Ключевые слова: модель векторного пространства, модель поиска, информационный поиск
В модели векторного пространства документ ![]() и запрос
и запрос ![]() представляются в виде векторов и релевантность рассчитывается по следующей формуле [1]:
представляются в виде векторов и релевантность рассчитывается по следующей формуле [1]:
![]() , ,
, ,
Где![]() , – векторное представление запроса,
, – векторное представление запроса, ![]() – векторное представление документа. В качестве векторов в эксперименте использовалась оценка веса запроса и нормированный вес термина в документе -
– векторное представление документа. В качестве векторов в эксперименте использовалась оценка веса запроса и нормированный вес термина в документе -![]() .
.
![]() ,
,
Где ![]() частота термина в запросе,
частота термина в запросе, ![]() обратная документная частота, вычисляемая по формуле:
обратная документная частота, вычисляемая по формуле:
![]() ,
,
где ![]() – размер базы документов,
– размер базы документов, ![]() – количество документов с данным термином.
– количество документов с данным термином.
![]() ,
,
В данном примере вес термина в документе учитывал только частоту термина, но возможны и другие варианты [2] взвешивания документа. Ручной подбор схемы взвешивания для коллекции документов займет большое время, проведем эксперимент для подбора схемы взвешивания используя одну из трех![]() ,
, ![]() или
или![]() c помощью генетического алгоритма, который получает на вход количество коэффициентов
c помощью генетического алгоритма, который получает на вход количество коэффициентов![]()
используемых в модели и возвращает подобранные коэффициенты. Общий алгоритм выглядит следующим образом:
-
Создается начальная популяция. Случайным образом из диапазона коэффициентов от
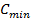 до
до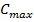 (диапазон устанавливается для каждого алгоритма), подбираем
(диапазон устанавливается для каждого алгоритма), подбираем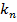 наборов коэффициентов и переводим их в двоичный вид.
наборов коэффициентов и переводим их в двоичный вид. - Вычисляем приспособленность хромосом. Оцениваем ошибку, для каждого набора коэффициентов.
- Выбираем двух родителей с наименьшей ошибкой для операции скрещивания.
- Выбор хромосом для операции мутации.
- Оценка приспособленности нового набора коэффициентов.
-
Если ошибка
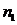 - набора больше заданной ошибки
- набора больше заданной ошибки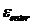 , то переходим к пункту 3, иначе пункт 7.
, то переходим к пункту 3, иначе пункт 7. - Полученный набор коэффициентов, который минимизирует ошибку, возвращается в модель поиска.
Рассмотрены более детально основные аспекты:
- Все коэффициенты генерируются изначально случайным образом по равномерному закону при ограничении сверху и снизу. Затем переводятся в двоичный вид, чтобы можно было применять операции скрещивания и мутации.
-
Ошибка оценивается по следующей формуле:
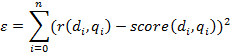
Где![]() , – средняя оценка документа
, – средняя оценка документа ![]() экспертами, по запросу
экспертами, по запросу![]() .
. ![]() – полученная релевантность документа
– полученная релевантность документа![]() , по запросу
, по запросу![]() .
.
Эксперимент.Для проверки эффективности применения генетического алгоритма (ГА), сравним полученные метрики оценки для двух систем по 30 запросам.
Полнота () вычисляется как отношение найденных релевантных документов к общему количеству релевантных документов:
Полнота характеризует способность системы находить нужные пользователю документы, но не учитывает количество нерелевантных документов, выдаваемых пользователю. Полнота показана на рисунке 1.

Рис.1. Полнота
В большинстве случаев ГА показывает лучшую полноту. Среднее значение полноты: ГА= 0,245; ВМ=0,153.
Точность () вычисляется как отношение найденных релевантных документов к общему количеству найденных документов.
Точность характеризует способность системы выдавать в списке результатов только релевантные документы. Точность алгоритмов показана на рисунке 2.
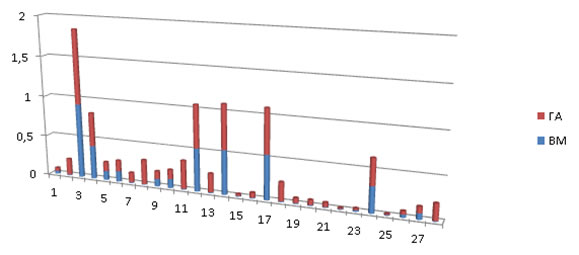
Рис.2. Точность
Среднее значение точности: ГА=0,207; ВМ=0,144.
Аккуратность () вычисляется как отношение правильно принятых системой решений к общему числу решений. Аккуратность алгоритмов показана на рисунке 3.
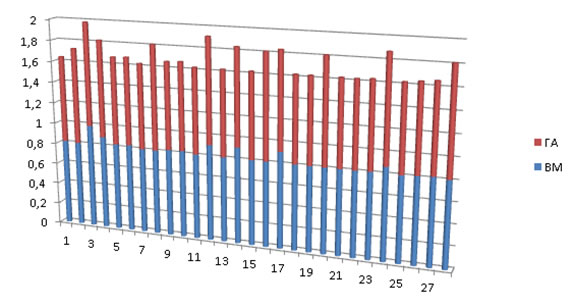
Рис.3. Аккуратность
Среднее значение аккуратности: ГА=0,87; ВМ=0,83.
Ошибка () вычисляется как отношение неправильно принятых системой решений к общему числу решений. Ошибка алгоритмов полказана на рисунке 4.

Рис.4. Ошибка
Среднее значение ошибки: ГА=0,153; ВМ=0,16.
F-мера () часто используется как единая метрика, объединяющая метрики полноты и точности в одну метрику. F-мера для данного запроса вычисляется по формуле:

Отметим основные свойства:
-

-
если
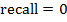 или
или 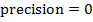 , то
, то 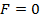
-
если
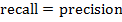 , то
, то 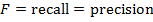
F-мера алгоритмов полказана на рисунке 5.
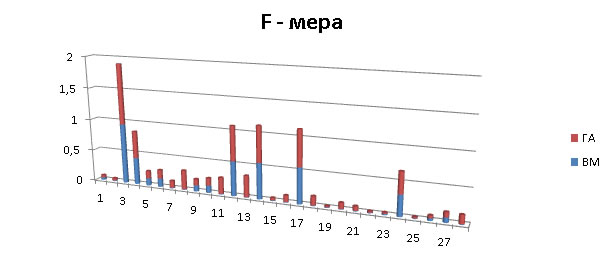
Рис.5. F-мера
Среднее значение f-меры: ГА=0,20; ВМ=0,14.
Таким образом, можно сделать вывод,Модификация с генетическим алгоритмом обладает лучшими значениями метрик, по сравнению с базовым алгоритмом. Но при этом не оправдана сама эффективность использования векторной модели для ранжирования, т.к. вычисление косинусной меры сходства между вектором запроса и каждым вектором документа коллекции, сортировка по релевантности и выбор лучших документов является довольно затратным процессом и требует выполнения десятков тысяч арифметических операций.
Литература:
1. Маннинг, Кристофер Д. Введение в информационный поиск. М. : Вильямс, 2011.
2. Дубинский А.Г. Некоторые вопросы применения векторной модели представления документов в информационном поиске // Управляющие системы и машины. 2001. № 4.